32bit vs 64bit
먼저 32bit CPU와 64bit CPU를 비교할 수 있다. 여기서 bit의 의미는 CPU 레지스터의 크기를 의미한다. CPU는 레지스터를 통해 주소와 값을 불러오고 연산을 처리하기 때문에 이는 CPU가 한 번에 처리할 수 있는 데이터의 크기를 의미한다. 즉 32bit 컴퓨터에서 메모리의 주소의 크기는 32bit(4 Byte)이고 64bit 컴퓨터에서 메모리의 주소의 크기는 64bit (8 Byte)인 것이다.
메모리 주소의 크기는 메모리의 크기와도 밀접한 관련이 있는데 CPU가 32bit이면 주소를 2^32 즉, 0xFFFFFFFF 까지만 표현 가능한데 2^32 = 4 * 10^9 (4GB) 이므로 4GB 이상의 RAM은 가지고 있어도 접근이 불가능하다. 따라서 32bit 컴퓨터에서는 4GB RAM까지만 사용 가능하다. 지금은 64bit CPU가 나오면서 주소를 2^64 = 16 * 10^18 (4EB)으로 이론상으로는 RAM 16엑사 바이트까지 주소 접근이 가능하지만 현실적으로는 16TB RAM까지 사용가능하다.
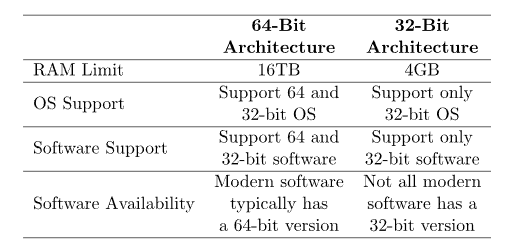
위에 표에서 볼 수 있듯 64bit CPU에서는 32bit OS를 깔 수 있지만 32bit CPU에서는 64bit OS를 깔 수 없다.
추가로 64bit 컴퓨터를 x64, 32bit 컴퓨터를 x86이라고 하는데
이는 x86은 인텔의 32bit CPU 8086 시리즈의 이름을 따서 32bit CPU를 의미한다고 보면 된다.
C언어의 int32_t, uint32_t ??
C언어에서 int, char 와 같은 자료형이 아닌 <stdint.h> 헤더 파일에 정의된 uint8_t 와 같은 자료형은 왜 존재할까? 이는 위의 CPU 스펙과 밀접한 관련이 있다. x86/x64 CPU, OS에 따라 크기가 다른 자료형이 있기 때문이다.
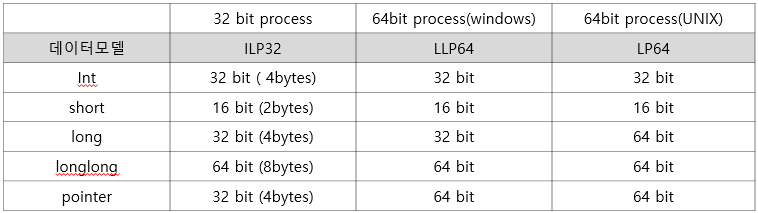
기본적으로 위에서 설명했던 것처럼 pointer의 크기는 x86과 x64 컴퓨터에서 다르고 같은 64bit CPU도 OS에 따라 자료형의 크기가 달라지게 된다. 특히 16bit CPU까지 가면 int 크기도 2 Bytes로 바뀔 수도 있는 것이다. 그래서 C프로그래밍을 할 때는 해당 프로그램이 동작하는 환경에 따라 자료형의 크기가 변하는 것을 막기위해 크기가 지정된 uint8_t와 같은 자료형을 써야하는 것이다.
요즘 누가 32bit, 64bit CPU를 써 라고 할 수 있겠지만 임베디드 개발에서는 PC가 아닌 Target MCU에서 프로그램이 실행되고 따라서 PC가 아닌 Target MCU의 환경을 고려하여 자료형을 써야하는 것이다. Windows 환경에서는 큰 차이가 나지 않지만 MCU에 따라 자료형의 크기가 큰 것이 메모리뿐만 아니라 실행 속도에서도 차이를 낼 수 있으므로 자료형을 해당 변수에 적합하게 설정해야 한다. 실제로도 임베디드 개발에서 실수형을 표현할 때 double이 아닌 float을 사용하는 것도 그 이유에서이다.
'Computer Science' 카테고리의 다른 글
| GCC란? 컴파일? 빌드? (0) | 2024.06.21 |
|---|---|
| OS - 8. (0) | 2024.05.18 |
| HTTP와 리퀘스트 메시지 (0) | 2023.07.26 |
| URL, URI란? (0) | 2023.07.25 |
| 네트워크 - 6. 응답 데이터가 웹 서버에서 웹 브라우저로 (0) | 2023.07.25 |
32bit vs 64bit
먼저 32bit CPU와 64bit CPU를 비교할 수 있다. 여기서 bit의 의미는 CPU 레지스터의 크기를 의미한다. CPU는 레지스터를 통해 주소와 값을 불러오고 연산을 처리하기 때문에 이는 CPU가 한 번에 처리할 수 있는 데이터의 크기를 의미한다. 즉 32bit 컴퓨터에서 메모리의 주소의 크기는 32bit(4 Byte)이고 64bit 컴퓨터에서 메모리의 주소의 크기는 64bit (8 Byte)인 것이다.
메모리 주소의 크기는 메모리의 크기와도 밀접한 관련이 있는데 CPU가 32bit이면 주소를 2^32 즉, 0xFFFFFFFF 까지만 표현 가능한데 2^32 = 4 * 10^9 (4GB) 이므로 4GB 이상의 RAM은 가지고 있어도 접근이 불가능하다. 따라서 32bit 컴퓨터에서는 4GB RAM까지만 사용 가능하다. 지금은 64bit CPU가 나오면서 주소를 2^64 = 16 * 10^18 (4EB)으로 이론상으로는 RAM 16엑사 바이트까지 주소 접근이 가능하지만 현실적으로는 16TB RAM까지 사용가능하다.
위에 표에서 볼 수 있듯 64bit CPU에서는 32bit OS를 깔 수 있지만 32bit CPU에서는 64bit OS를 깔 수 없다.
추가로 64bit 컴퓨터를 x64, 32bit 컴퓨터를 x86이라고 하는데
이는 x86은 인텔의 32bit CPU 8086 시리즈의 이름을 따서 32bit CPU를 의미한다고 보면 된다.
C언어의 int32_t, uint32_t ??
C언어에서 int, char 와 같은 자료형이 아닌 <stdint.h> 헤더 파일에 정의된 uint8_t 와 같은 자료형은 왜 존재할까? 이는 위의 CPU 스펙과 밀접한 관련이 있다. x86/x64 CPU, OS에 따라 크기가 다른 자료형이 있기 때문이다.
기본적으로 위에서 설명했던 것처럼 pointer의 크기는 x86과 x64 컴퓨터에서 다르고 같은 64bit CPU도 OS에 따라 자료형의 크기가 달라지게 된다. 특히 16bit CPU까지 가면 int 크기도 2 Bytes로 바뀔 수도 있는 것이다. 그래서 C프로그래밍을 할 때는 해당 프로그램이 동작하는 환경에 따라 자료형의 크기가 변하는 것을 막기위해 크기가 지정된 uint8_t와 같은 자료형을 써야하는 것이다.
요즘 누가 32bit, 64bit CPU를 써 라고 할 수 있겠지만 임베디드 개발에서는 PC가 아닌 Target MCU에서 프로그램이 실행되고 따라서 PC가 아닌 Target MCU의 환경을 고려하여 자료형을 써야하는 것이다. Windows 환경에서는 큰 차이가 나지 않지만 MCU에 따라 자료형의 크기가 큰 것이 메모리뿐만 아니라 실행 속도에서도 차이를 낼 수 있으므로 자료형을 해당 변수에 적합하게 설정해야 한다. 실제로도 임베디드 개발에서 실수형을 표현할 때 double이 아닌 float을 사용하는 것도 그 이유에서이다.
'Computer Science' 카테고리의 다른 글
| GCC란? 컴파일? 빌드? (0) | 2024.06.21 |
|---|---|
| OS - 8. (0) | 2024.05.18 |
| HTTP와 리퀘스트 메시지 (0) | 2023.07.26 |
| URL, URI란? (0) | 2023.07.25 |
| 네트워크 - 6. 응답 데이터가 웹 서버에서 웹 브라우저로 (0) | 2023.07.25 |